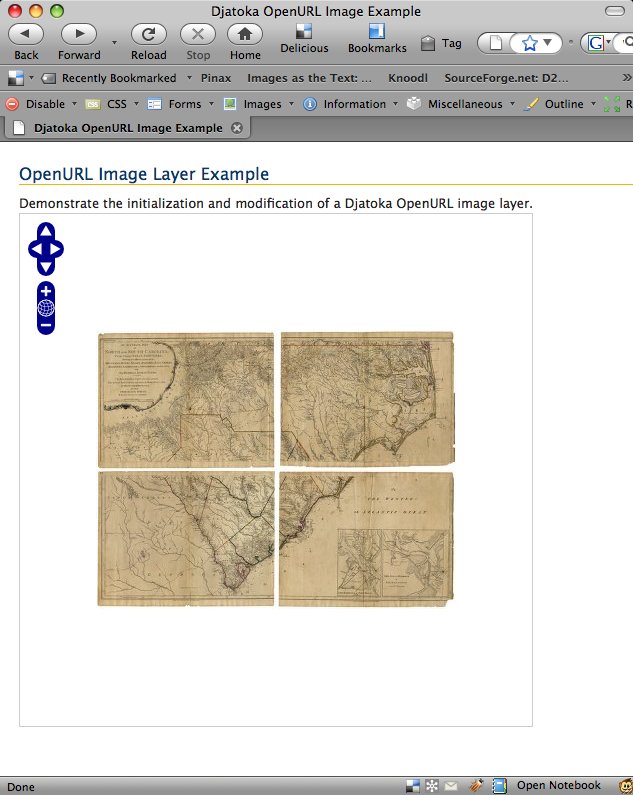
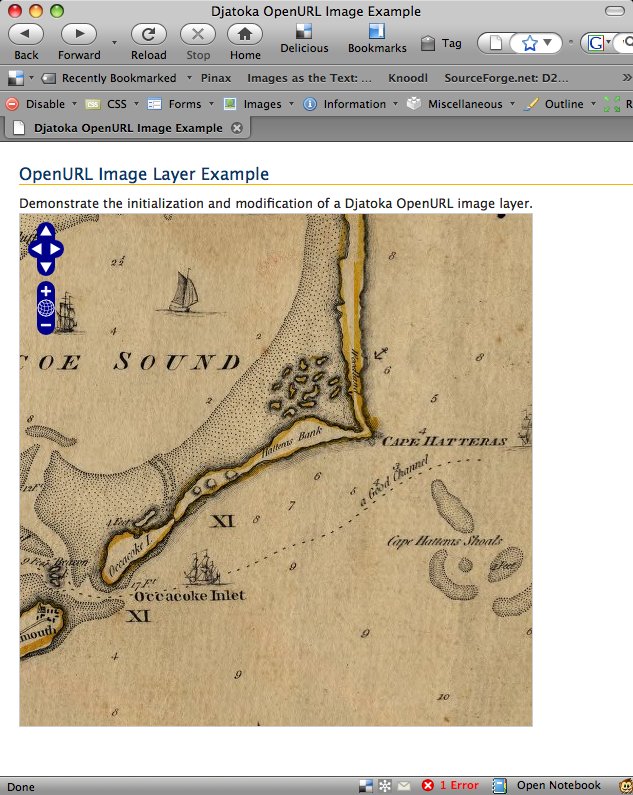
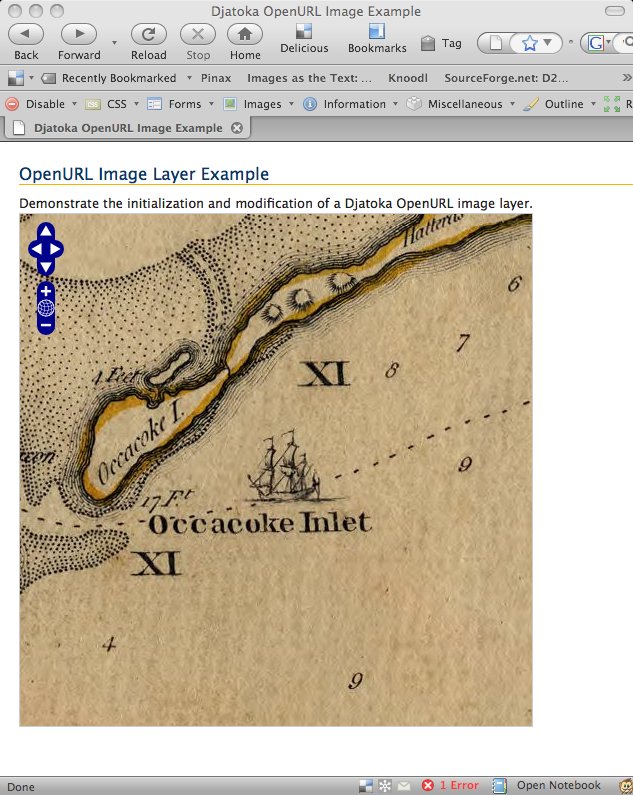
After a lot of messing around and some false starts, I've developed a Javascript class that supports Djatoka's OpenURL API. I've been testing it on JPEG2000 images created with ContentDM in the UNC Library's digital collections, with a good deal of success. The results are not yet available online, because I don't have a public-facing server I can host it on, but the source code is up on github here.
Instructions:
Install Djatoka. Incidentally, in order to get this in the queue for installation on our systems, I had to make Djatoka work on Tomcat 6. The binary doesn't work out of the box, but when I rebuilt it on my system (RHEL 5), it worked fine.
Copy the adore-djatoka WAR into your Tomcat webapps directory. Follow the instructions on the Djatoka site to start the webapp.
Grab a copy of OpenLayers. Put the OpenURL.js file in lib/OpenLayers/Layer/ and run the build.py script.
To just run the demo, copy the djatoka.html, the OpenLayers.js you just built, and the .css files from OpenLayers/theme/ and from the examples/ directory, as well as the OpenLayers control images from OpenLayers/img into the adore-djatoka directory in webapps. You should then be able to access the djatoka.html file and see the demo.
This all comes with no guarantees, of course. It seems to work quite well with the JPEG2000 images I've tested, and the tiling means that each request of Djatoka consumes an equal amount of resources. I've run into OutOfMemoryErrors when requesting full-size images, but this method loads them without any problem.
Update (2009-01-05 14:37): I've posted a fix to the OpenURL.js script for a bug pointed out to me by John Fereira on the djatoka-devel list. If you grabbed a copy before now, you should update.
Update: screenshots --