Let's look at the same document I talked about last time: http://papyri.info/ddbdp/p.ryl;2;74/source (see also http://papyri.info/ddbdp/p.ryl;2;74/). We can visualize the document structure using Graphviz and a spot of XSLT (click for high-res):
 |
| tree structure of a TEI document |
It's a fairly flat tree. As an XML document, it has to be a tree, of course, and TEI leverages this built-in "tree-ness" to express concepts like "this text is part of a paragraph" (i.e. it has a tei:p element as its ancestor). In line 1, for example, we find
<supplied reason="lost">Μάρ</supplied>κοςmeaning the first three letters of the name Markos have been lost due to damage suffered by the papyrus the text was written on, and the editor of the text has supplied them. The fact that the letters "Μάρ" are contained by the supplied element, or, more properly that the text node containing those letters is a child of the supplied element, means that those letters have been supplied. In other words, the parent-child relationship is given additional semantics by TEI. We already have some problems here: the child of supplied is itself part of a word, "Markos", and that word is broken up by the supplied element. Only the fact that no white space intervenes between the end of the supplied element and the following text lets us know that this is a word. It's even worse if you look at the tree version, which is, incidentally, how the document will be interpreted by a computer after it has been parsed:
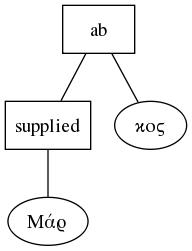
There's no obvious connection here between the first and second halves of the name. And in fact, if we hadn't taken steps to prevent it, any program the processed the document might reformat it so that "Mar" and "kos" were no longer connected. We could solve this problem by adding more elements. As the joke goes, "XML is like violence. If it isn't working, you're not using it enough." We could explicitly mark all the words, using a "w" element, thus:
<w><supplied reason="lost">Μάρ</supplied>κος</w>or

which would solve any potential problems with words getting split up, because we could always fix the problem—we would know what all the words are. We could even attach useful metadata, like the lemma (the dictionary headword) of the word in question. We don't do this for a couple of reasons. First, because we don't need to. We can work around the splitting-up of words by markup. Second, because it complicates the document and makes it harder for human editors to deal with, and third, because it introduces new chances for overlap. Overlap is the Enemy, as far as XML is concerned. The more containers you have, the greater the chances one container will need to start outside another, but finish inside (or vice versa). Consider that there's no reason at all a region of supplied text shouldn't start in the middle of one word and end in the middle of another. Look at lines 5-6 for example:
... οὐ̣[χ ἱκανὸν εἶ-]A supplied section begins in the middle of the third word from the end of line five, and continues for the rest of the line. The last word is itself broken and continues on the following line, the beginning of which is also supplied, that section ending in the middle of the second word on line six. This is a mess that would only be compounded if we wanted to mark off words.
[ναι εἰ]ς
This may all seem like a numbing level of detail, but it is on these details that theories of text are tested. The text model here cares about editorial observations on and interventions in the text, and those are what it attempts to capture. It cares much less about the structure of the text itself—note that the text is contained in a tei:ab, an element designed for delineating a block of text without saying anything about its nature as a block (unlike tei:p, for example). Visible features like columns, or text continued on multiple papyri, or multiple texts on the same papyrus would be marked by tei:divs. This is in keeping with papyrology's focus on the materiality of the text. What the editor sees, and what they make of it is more important than the construction of a coherent narrative from the text—something that is often impossible in any case. Making that set of tasks as easy as possible is therefore the focus of the text model we use.
What I'm trying to get at here is that there is Theory at work here (a host of theories in fact), having to do with a way to model texts, and that that set of theories are mapped onto data structures (TEI, XML, the tree) using a set of conventions, and taking advantage of some of the strengths of the data structures available. Those data structures have weaknesses too, and where we hit those, we have to make choices about how to serve our theories best with the tools we have. There is no end of work to be done at this level, of joining theory to practice, and a great deal of that work involves hacking, experimenting with code and data. It is from this realization, I think, that the "more hack, less yack" ethic of THATCamp emerged. And it is at this level, this intersection, this interface, that scholar-programmer types (like me) spend a lot of our time. And we do get a bit impatient with people who don't, or can't, or won't engage at the same level, especially if they then produce critiques of what we're doing.
As it happens, I do think that DH tends to be under-theorized, but by that I don't mean it needs more Foucault. Because it is largely project-driven, and the people who are able to reason about the lower-level modeling and interface questions are mostly paid only to get code into production, important decisions and theories are left implicit in code and in the shapes of the data, and aren't brought out into the light of day and yacked about as they should be.
